 lucasdanb.org
lucasdanb.org
lucasdanb.org
lucasdanb.org
A neural network trained on videos of powerlifting competitions to identify when a lift is good. I collaborated with my friend Leah to splice videos into training batches, build a model, and a frontend interface. All our code is here, and this is the actual website.

We chose this dataset for a project partially because we knew wouldn't have to manually cut and label data. Videos of powerlifting meets are usually hours long, shot from a constant angle, and have a marker on screen of exactly when each lift ends and begins. The frame to the right is an example of how we'd detect the end of a lift. Three lights show up on screen usually about 1-2 seconds after a lifter re-racks the bar. Our script detects the lights, records how many are white (2 or more white lights is a passing lift), and then chops an eight-second long 300 by 300 pixel portion of the video right before the timestamp when the lights were detected. This eight-second clip is our x data point, and the integer number of white lights is our y data point. With our script, we needed only to change the location of the lights and the corners of the crop per video. Each lift has a dataset of about 500 videos currently.
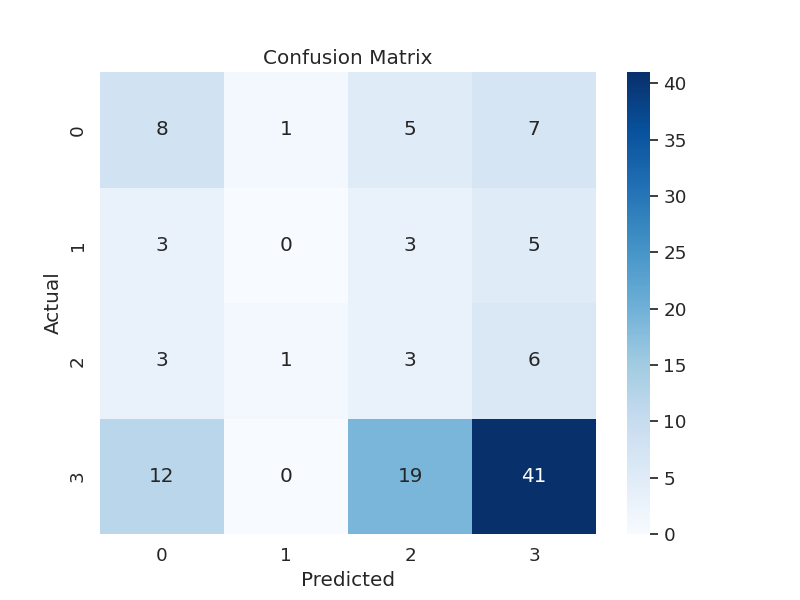
The datasets are heavily biased in the direction of three white-light lifts (by far most lifts are good lifts). In fact, when training the models without any data modification, they frequently reached a local loss minima of just labelling every single video as a three-light lift:
To get around this, we actually duplicated data in our training sets until every category had the same number of videos. In order to prevent overfitting on the repeated videos, we including a function that randomly increased or decreased each greyscale pixel value (0 - 255) in each video by a small amount. Each model reached about 0.9 accuracy on training data with this method. We left the testing and validation sets alone, meaning they were still biased toward three-light videos, and each model only reached about 0.44 accuracy on test and 0.65 on validation after 20 epochs.

Per TensorFlow recommendation, we first tried a 2 + 1 dimensional convolutional neural network. However, we ran into issues when trying to train the model distributed across multiple machines because of custom layers. With that, we settled on a LSTM (Long Short-Term Memory) model. We included a 2D convolutional layer followed by a 2D pooling layer in order to compress the video data before it entered the LSTM. Long Short-Term Memory models require a lot of memory to run (who would've thought) and our hardware was deep into swap space taking days to run without any compression.
You can also see the shape of the data we worked with in that diagram. The input data follows the format (frames = seconds * FPS, height, width, color channels), which for us was (64 = 8 * 8, 300, 300, 1). The output is just four nodes for 0, 1, 2, or 3 white lights. Here's what a lift looked like to our model:

This was honestly the most fun part of the whole project, at least for me. Because processing video data is so computationally heavy, I set up a Beowulf cluster of 5 hand-me-down computers that we could leave running overnight to train our models. Four of the computers didn't have GPUs, and they also had outdated processors that couldn't use AVX instructions, meaning we had to make a custom TensorFlow installation that could run on them. Each computer is running Ubuntu server, and they're linked up over an Ethernet switch. The laptop on top of the stack is the master node:


This was honestly overkill and the desktops were so slow that they barely provided enough extra power to make the whole cluster worth it, but it was a good excuse to learn how to set it up and use MPI.
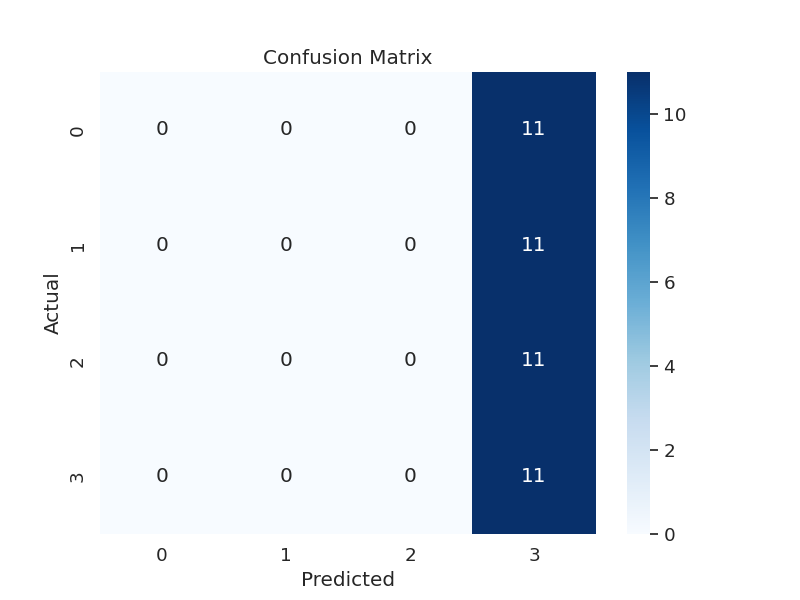
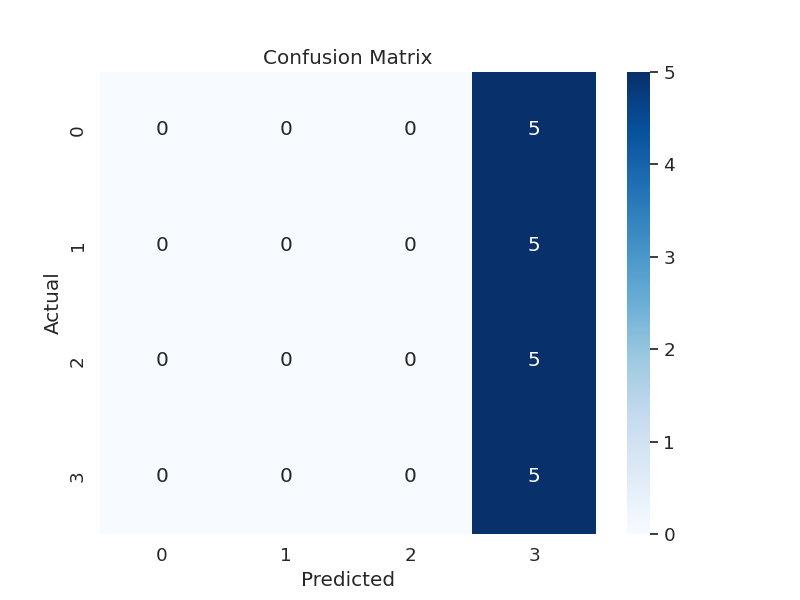
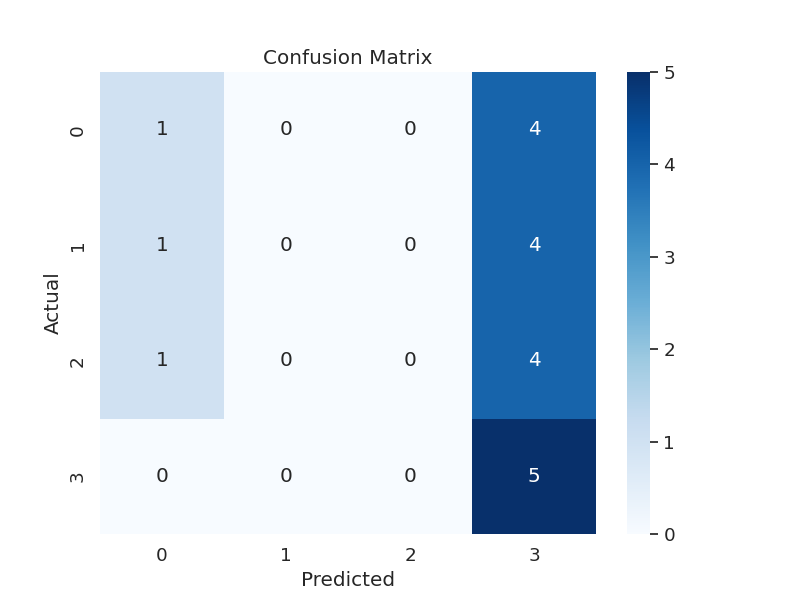
Here are our most recent confusion matrices for squat, bench, and deadlift respectively:

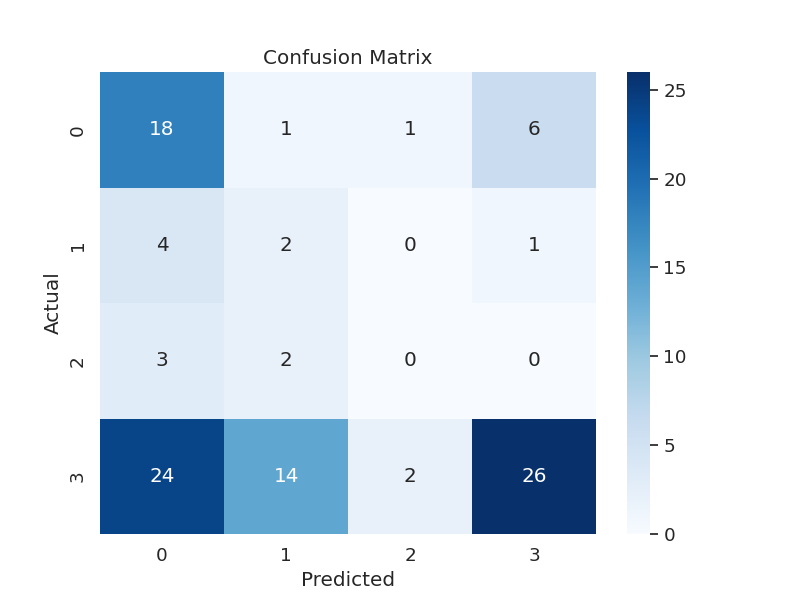
This is basically negligible accuracy. Again, the model only gets away with appearing slightly trained because of the data bias toward 3-light lifts. When evaluating with compressed test data (data points removed to even out categories), the accuracy is even lower - close to 0.25, which is the same as randomly guessing.
There are a couple options for trying to improve this - we could decrease video compression prior to the LSTM layer, build a larger dataset so that train data could be removed instead of duplicated for even categories, add batch normalization or other processing layers - but unfortunately, our data is simply not good enough. Even looking at the videos ourselves as actual human powerlifters, we cannot classify them much better than our network. The only clear distinction is between obviously succeeding (3 lights) and totally incomplete (0 lights) lifts. But this is not very useful for an application - if you don't even complete the lift, of course you failed it. The idea was that if you completed the lift, but weren't sure about your form, this network could give you a verdict on it. In other words, development on this project is finished. But the inacurrate product will still be left up in the website.